Bias in business: minimising bias with responsible machine learning

Amelia Teh
Responsible machine learning is no longer a philosophical dialogue, but a serious consideration for everyday practitioners to ensure a fair and positive impact to society. While this complex topic continues to expand with growing literature, we would like to share some approaches we have undertaken to reduce bias and build inclusive solutions.
Despite the optimism towards using AI to solve big data problems and advance system capabilities, the ethics of using AI and machine learning (ML) algorithms have come under scrutiny with concerns over data bias, transparency and accountability.
A study in 2019 found that an AI algorithm, used on more than 200 million people in US hospitals and insurance companies, heavily favoured white patients over black patients when predicting individuals who would likely benefit from extra medical care. Despite the exclusion of race in the algorithm, the problem stemmed from a determining variable – the patients’ healthcare cost history, which highly correlated to race. As black patients were often less able to pay for a higher standard of care due to multiple factors, the algorithm learned and determined that they were not entitled to such a standard.
Having made this discovery, the UC Berkeley team worked with the company responsible for developing the AI tool to find other variables besides cost through which to assign the expected risk scores, reducing bias by 84 percent.
The unintentional bias that has crept into the US healthcare system is one of several high profile cases where AI systems have caused harm to marginalised groups. It is also one of many scenarios demonstrating the significant impact data scientists and developers of ML systems have on peoples’ lives.
Building ML models involves human decision-making and data collected from real-world events which represent human behaviours in different situations. Humans are biased in one way or another, so it would be naive to expect ML models to be exempt from biases without further intervention.
While there is no way to completely banish bias, we must try to reduce it to a minimum. At GBG, developing ML models responsibly is a continuous journey. Based on the experience and findings from models developed/deployed led by Adam Emslie (Head of Analytics), we minimise bias in three main ways:
- Ethical data collation and preparation: We consider ethics in our dataset design to account for data diversity.
- Interpretable outcomes: We ensure process transparency for interpretable prediction outcomes.
- Human in-the-loop processes: We enable human in-the-loop processes to optimise data learning and solve problems effectively.
The path to responsible ML is a collaborative one. All of us are stakeholders with the responsibility of concretely implementing ethics, safety and inclusivity into GBG ML solutions. To illustrate our approach with references to the work that we do:
Ethical data collation and preparation
Biased data is the primary source of bias in ML, summed up in the phrase: garbage in, garbage out. ML is an approach to programming where systems 'learn' patterns by analysing data - if we enter biased data into a system, we will receive biased results. Thus, correct data collation is the critical first step in model development.
Fair and transparent
In the context of building fraud prediction model for a bank’s application channels, we not only hash the applicants’ personal data in compliance with privacy and fairness, but also ensure that informed consent is obtained from the bank on what data is gathered, for what purpose, and for how long.
As best practice, we inspect a bank’s application trends to determine the appropriate training data period for machine learning. This exercise prevents negative discrimination in the model built on this data. In real-world scenarios, certain months may see higher or lower number of applications than usual due to activities conducted by the bank, such as a promotion or marketing campaign (Figure 1). The unusual period is excluded from the training dataset because no similar patterns will occur in the future, and this minimises bias where certain groups could be over or underrepresented as an outcome of the promotion.
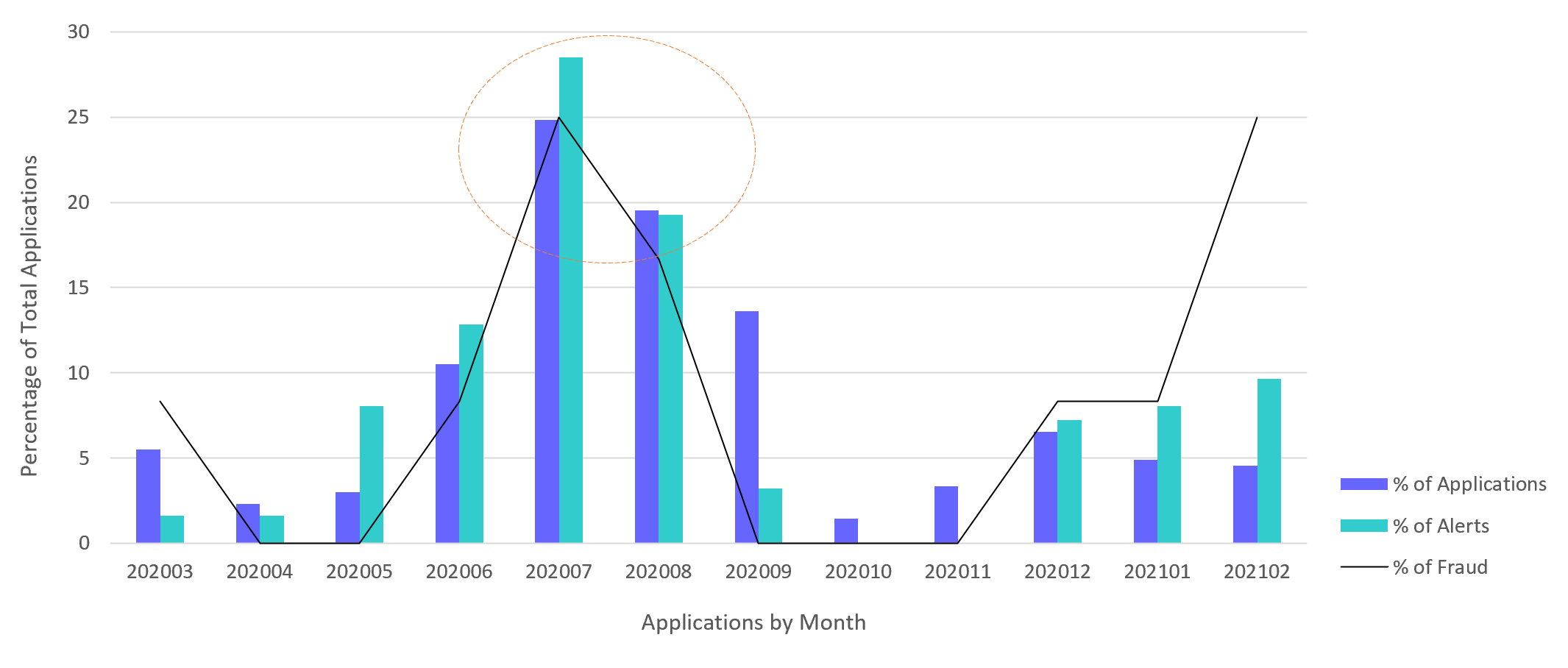
Figure 1: Example of data inspection showing an unusually high number of applications in July and August over a 12-month period.
Diverse data
The bias presented in the US healthcare tool could have been prevented if more variables (or model features) were used in the algorithm. In fraud detection, expanding predictors by leveraging external data sources such as device fingerprint or behavioural biometrics minimises bias and strengthens prediction. Figure 2 illustrates the combination of internal (transaction data) and external data (devised fingerprint and behavioural biometrics) used as model features in transaction monitoring to detect fraud, without utilising sensitive data attributes like age, gender, race, etc.
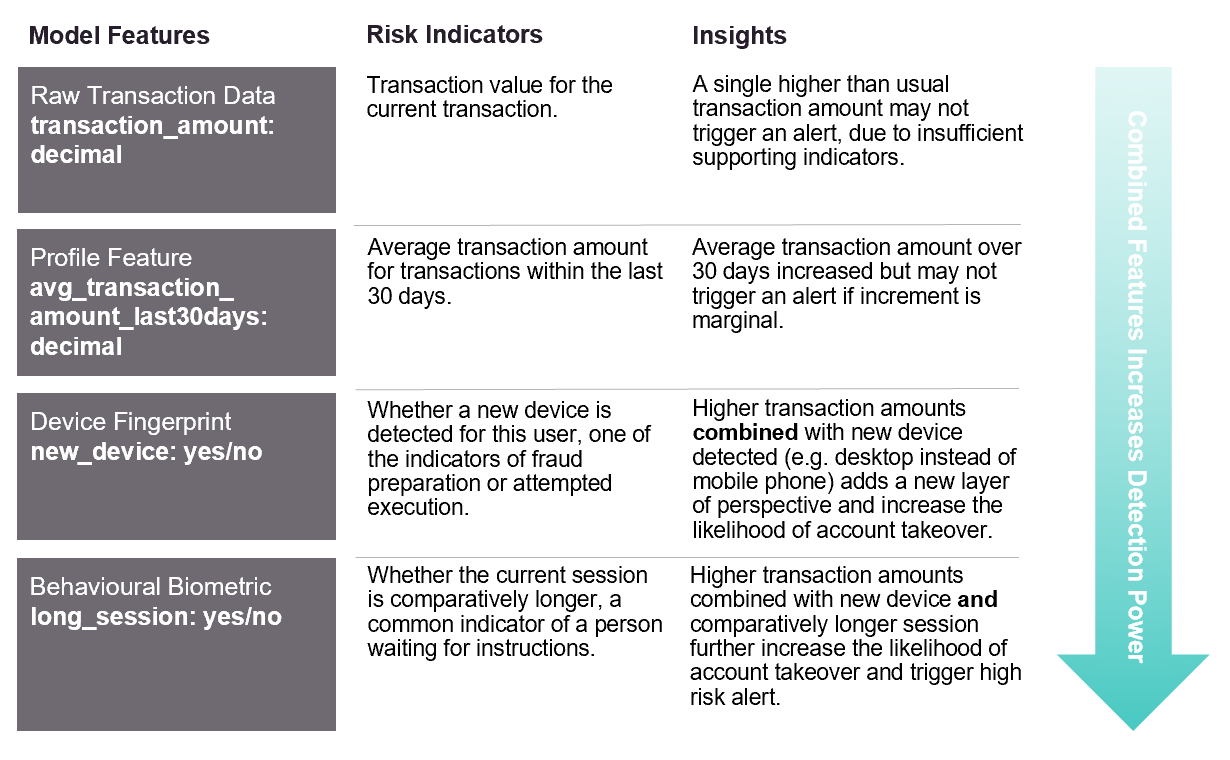
Figure 2: External data enriches internal data with new dimensions and insights to strengthen detection.
Interpretable outcomes
The interpretability of machine learning predictions is no longer limited to understanding how the model works, but whether we can trust the model to avoid the inherent biases which could lead to unintended harmful outcomes.
Visibility on the features influencing a model’s prediction lets us validate if the model is making its prediction for the right reasons. We can then make the decision to exclude or reengineer harmful features.
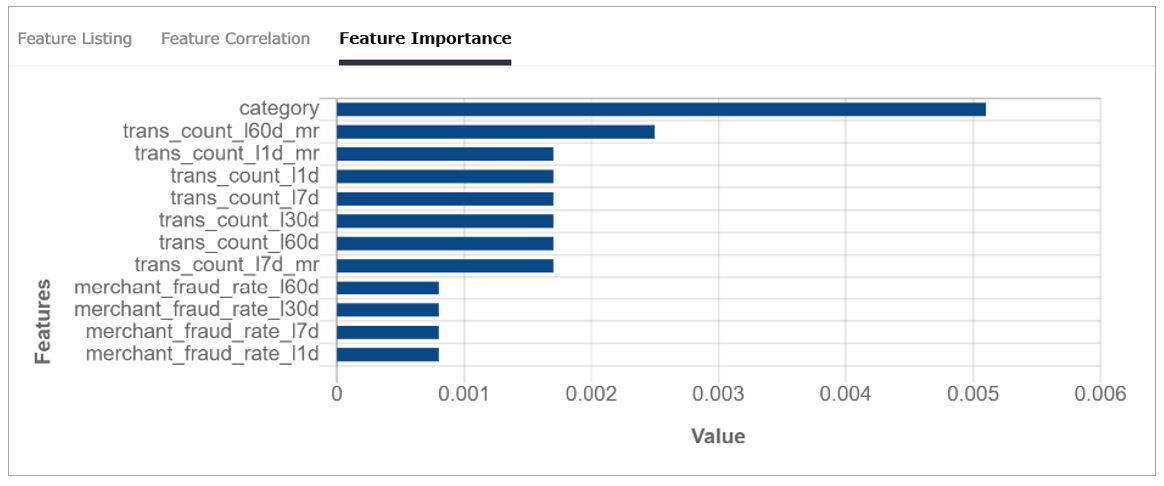
Figure 3: A Feature Importance chart extracted from Instinct and modified for brevity. Each feature contributing to the model’s output is ranked by its predictive value – “category” (transaction type) is relatively more important than “trans_count_l60d_mr” (transaction count in the last 60 days) in contributing to the model’s decision.
Human in-the-loop processes
Enabling subject-domain-experts as human-in-the-loop reviewers in the important processes of the ML system lifecycle is crucial in mitigating bias. Transparency on model interpretability is one example where domain experts and data scientists collaborate to assess and make decisions about harmful features. After a model has been developed, a domain expert can verify some of the results from the model to ensure the performance is aligned with the business objectives and avoid unintentional biases.
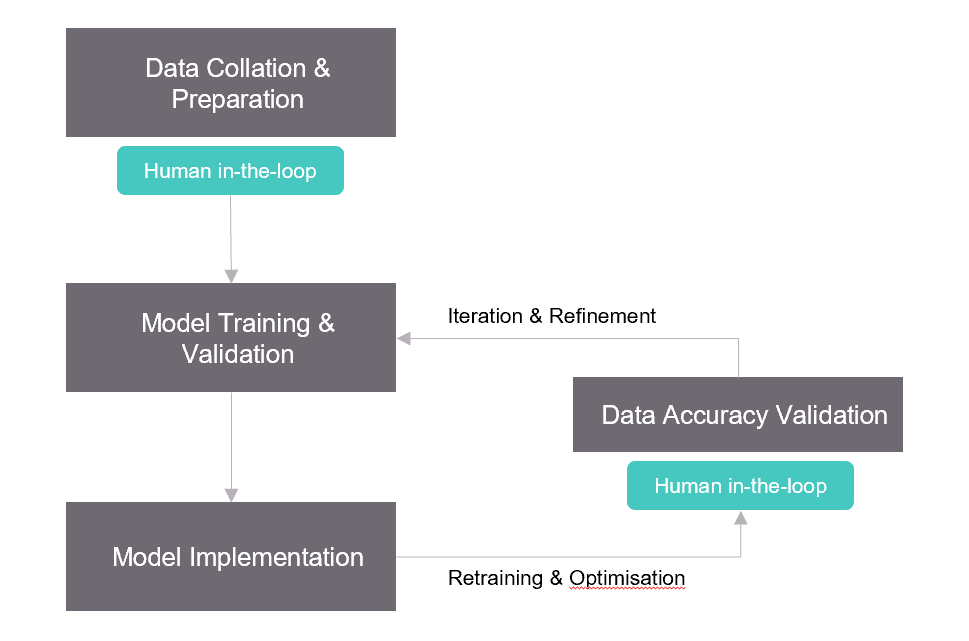
Figure 4: A high-level overview of human augmentation in the key processes of an ML system lifecycle.
What’s next?
Responsible ML is still in its infancy, with a long journey ahead. We continuously explore and experiment ideas, including incorporating a bias evaluation tool (threshold-effect analysis). If you have any questions about Responsible ML, or the work we are doing, feel free to reach out to us at contact@gbgplc.com.
References
- “Racial Bias Found in a Major Health Care Risk Algorithm”, 2019, https://www.scientificamerican.com/article/racial-bias-found-in-a-major-health-care-risk-algorithm/
- “The Responsible Machine Learning Principles”, 2018, https://ethical.institute/principles.html
- “What Do We Do About Biases in AI”, 2019, https://hbr.org/2019/10/what-do-we-do-about-the-biases-in-ai
Sign up for more expert insight
Hear from us when we launch new research, guides and reports.