Complete customer onboarding
Onboard more customers with complete identity confidence and multi-layered protection against identity fraud.

Why GBG
Build trust with us
Every day we work behind the scenes to ensure your business can transact with confidence around the world.

Trusted expertise
Delivering definitive identity verification for over 30 years.

Global network
Bringing local market insights from over 1000 identity experts.

Global onboarding
Optimising onboarding for billions of your customers each year.

Global protection
Verifying, proving and protecting your business every second.
Features
See what GBG can do for your business
VERIFY
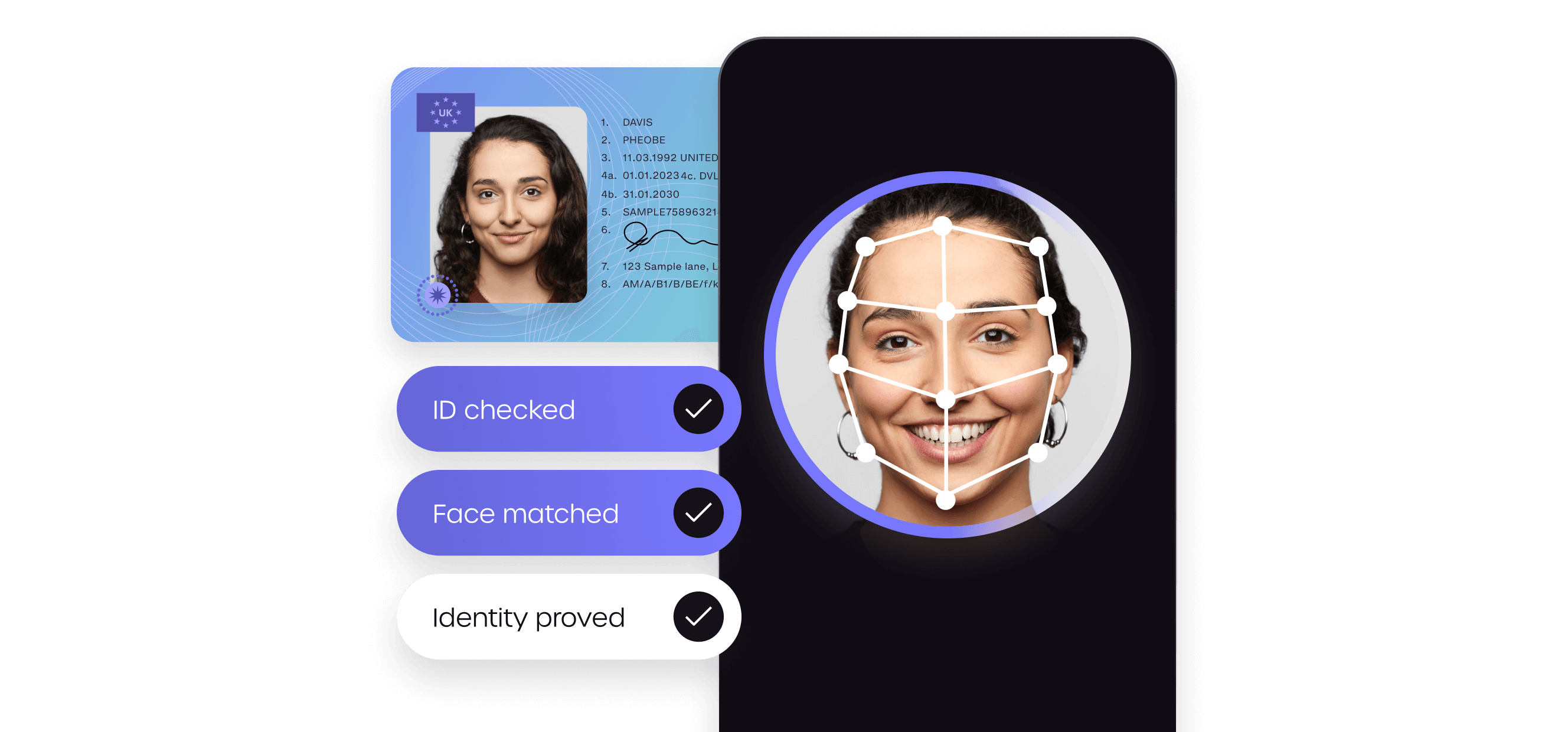
Identity verification
Trusted identity verification technology for smooth and secure customer onboarding worldwide.

GLOBAL IDENTITY
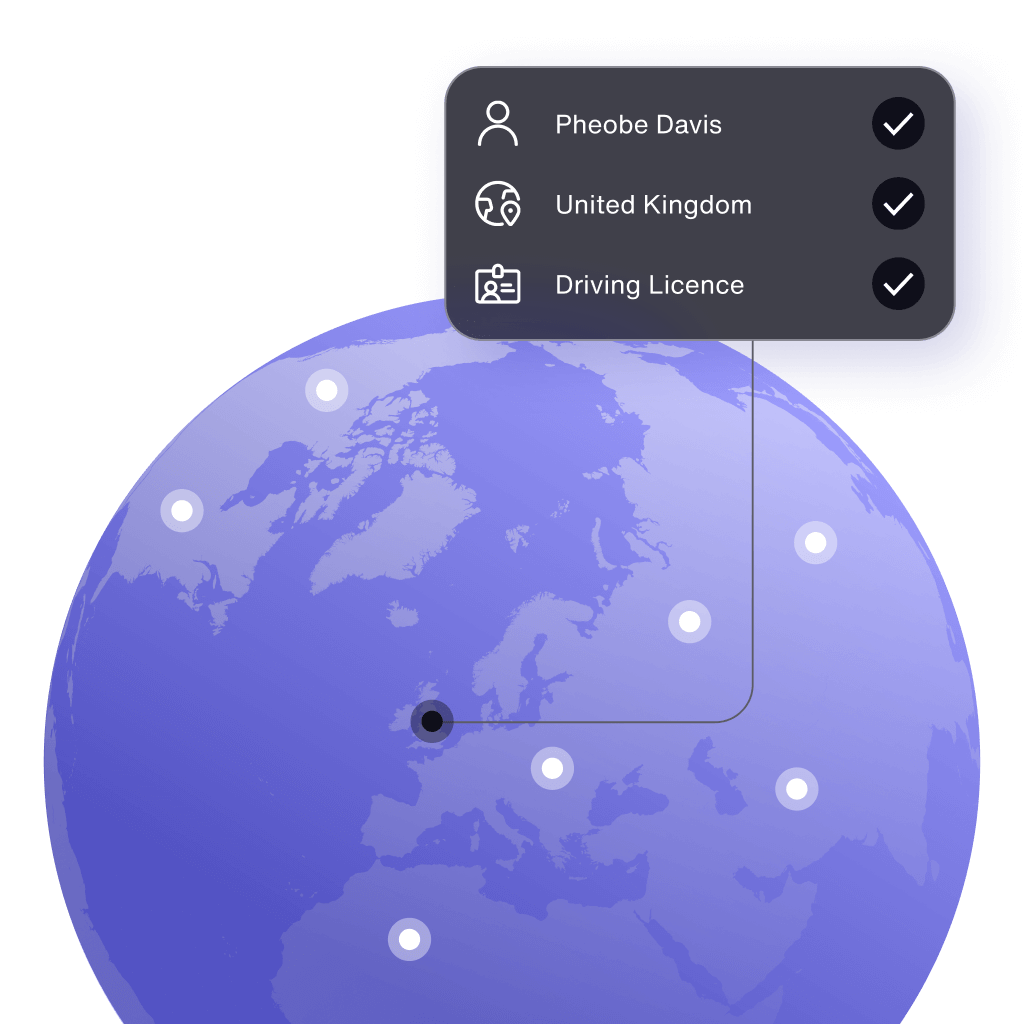
Customer onboarding
Wherever your business is going, get more good customers onboard:
- Data cover in 50+ countries
- Document cover in 196 countries
- Global library of 8500+ IDs
- Secure identity fraud detection
PROTECT
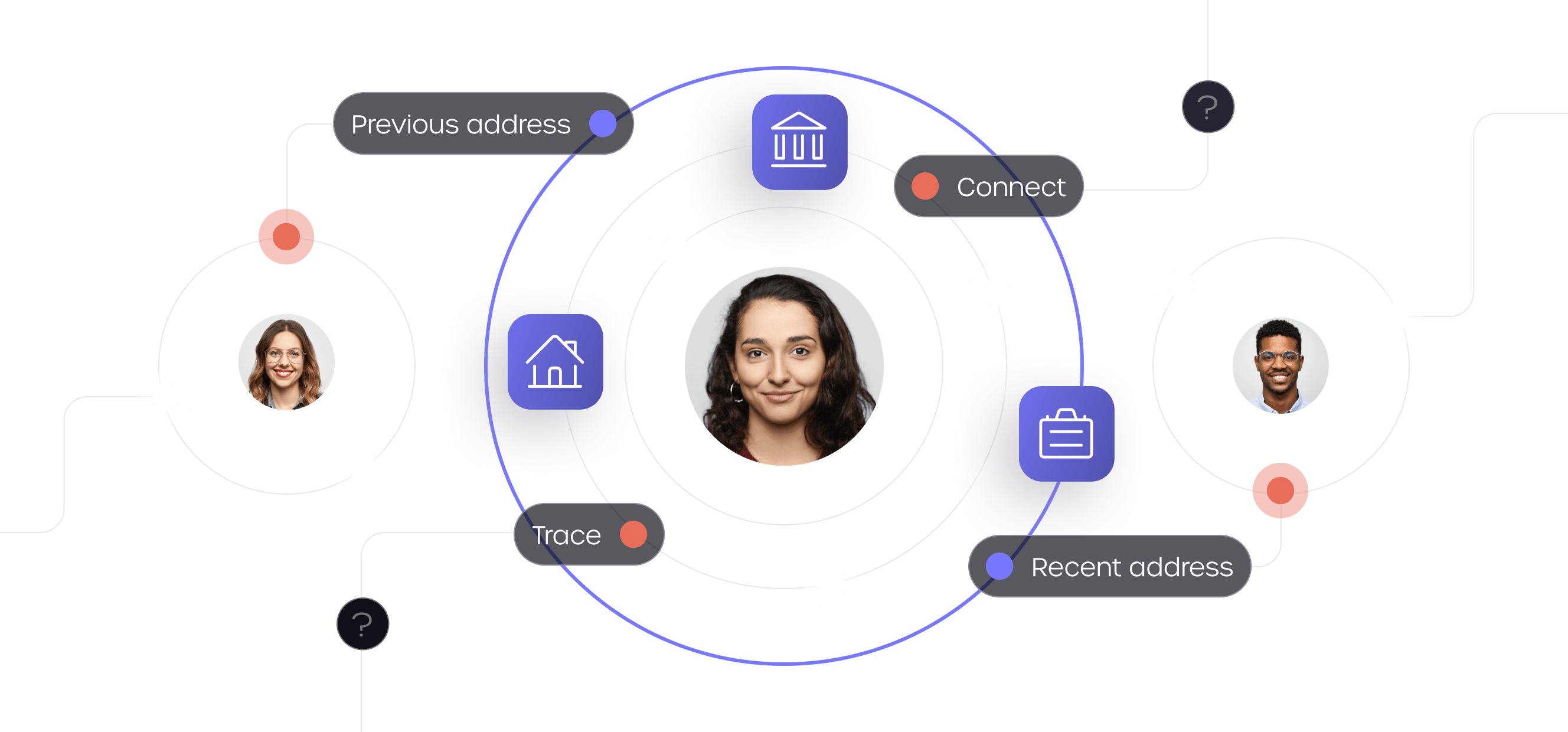
Fraud prevention
Eliminate fraud and fast track genuine customers with multi-layered protection that keeps criminals out.

GLOBAL ACCURACY
GBG Identity Score
Move the dial on digital identity with the identity confidence metric that optimises your customer onboarding.
- Match accuracy
- Match integrity
- Match count

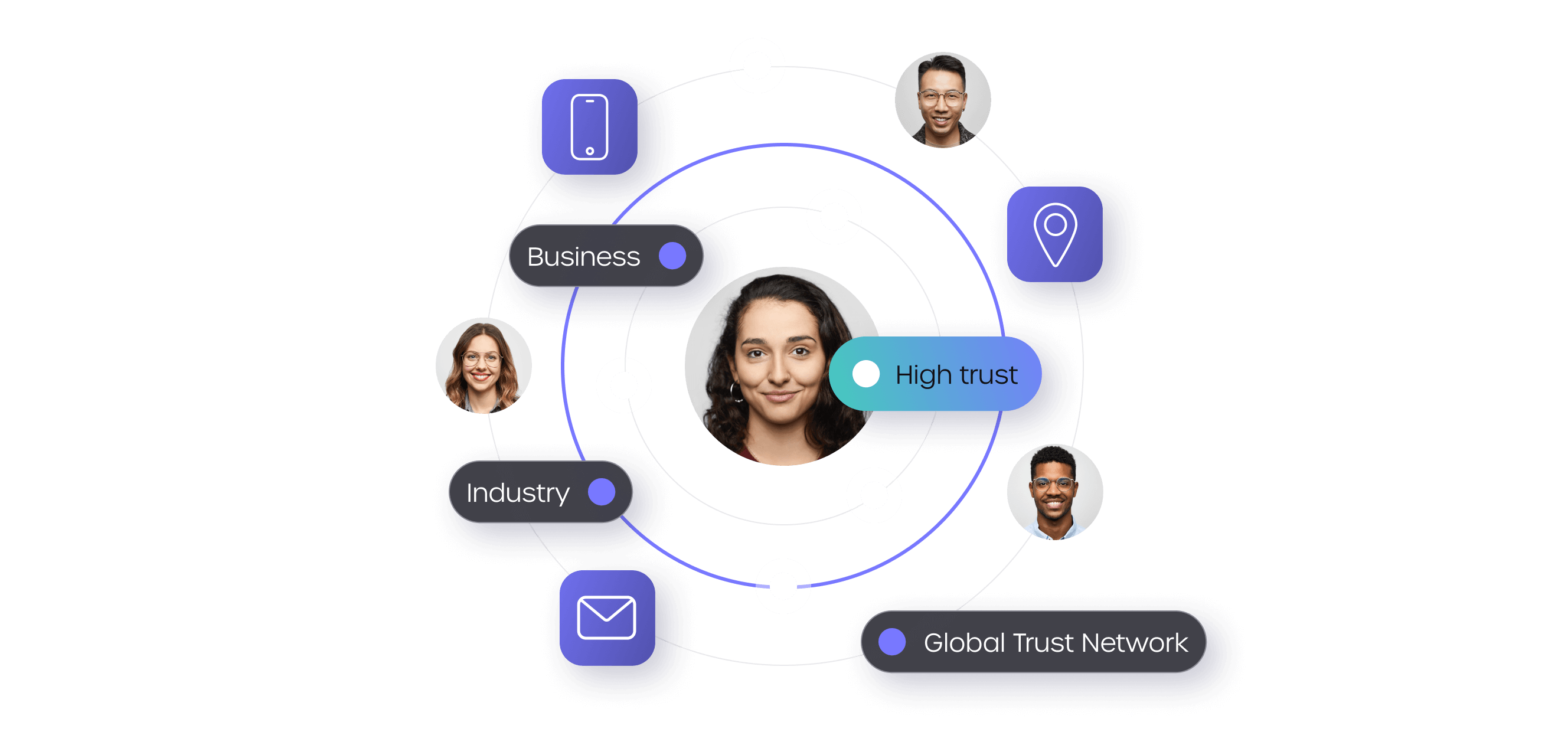
CONSUMER INTELLIGENCE
GBG Trust Network
Powerful insights from millions of global customer interactions.

Our Customers
Trusted by thousands of businesses worldwide
"We needed a reliable system and database that could help us verify an individual so that we could protect the business and our customers from fraud."


